
本文来源于微信公众号“ 自然语言处理算法与实践”,作者:烛之文
1、前言
随着大模型(large language models)的发展,导致网络上信息越来越难以判断是不是AI生产,这也带来更多的假信息涌现在人们的日常生活中。而如何消除大模型带来的信息不安全隐患,也成为当下一个重要的研究热点。目前已有学者提出给大模型加水印(Watermark)的技术来解决这个问题,他们的技术方案可以大体分成两类:
(1)修改分布:其通过一个密钥来修改next token的分布,然后通过检测指标来判断是否是大模型产生;代表论文有[1]、[2]、[3];
(2)修改采样:修改原始的采样的过程,最后同样利用检测指标来判断;代表论文有[4]、[5];
其中文献[1]:A Watermark for Large Language Models 是这个方向的开山之作,本次我们主要分享其详细的技术思路,了解下如何给大模型加水印。
2、Watermark
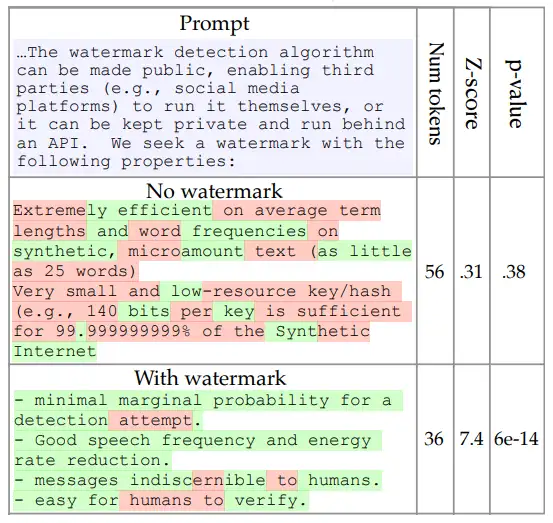
如上图,其思路是将生成的token分类两类集合:绿色、红色;加了水印的大模型,在生成文本时,来自绿色集合的token更多,其对应的Z-score指标值会比较大;相反,没有水印(人工的自然文本)来自绿色集合的token占比就比较低。其中p-value代表假阳性的概率,如p=6e-14意味在此情况下,生成的文本来自人工的概率为6e-14。
在知道大致思路后,接下来的问题就是:在大模型生成的时候,如何产生绿色、红色集合,以及Z-score怎么计算。
论文中提出了两个版本:(1)a sample watermark (2)a sophisticated watermark,即对应一个简单版本和一个比较复杂的版本。而所谓的复杂,主要是对红色集合(red list)产生的方式来区分的,前者产生红色集合比较固定、hard,后者产生方式比较灵活、soft,而灵活意味着需要更复杂的计算。先说下简单版本的思路。
2.1 sample watermark

其思路如下:
(1)输入prompt序列信息,
(2)在利用大模型进行解码时,对于t时刻序列,对应的token概率 是由 序列产生的;
(3)利用 token产生一个hash值,然后利用该值产生一个随机种子;
(4)基于产生的随机种子,将词表随机分成两个等大小的绿色词表集合(green list,G)和红色词表集合(red list,R)
(5)在生成 token时,只从绿色集合采样,拒绝从红色集合采样。
在按上述方式进行解码,就等于在大模型输出时加了水印,而输出的结果人是正常看不出来;这样就设计了一个检测指标来判断是否是大模型生成。该检测指标为z-score:
其中 为来自绿色集合中token的数量,T为生成序列的长度;代表的含义的按上述的生成过程,产生的绿色集合token数量变量 服从 均值为,方差为的分布 (为何是这个分布,这里有个理论分析过程,这里就不展开说,有兴趣看原文);按上述公式转化后,z指标就服从标准正态分布。当z>4时,生成的序列不是大模型产生的概率约为3*10-5(该值正态分布查表得到)。
以上就是sample watermark的整体过程,但它产生的hard red list会存在以下问题:
(1)很难处理低熵的文本加水印;这里低熵是指文本序列很固定,生成的时候没有太多的多样性,如输入“好好学习,”模型大概率会输出“天天向上”;当大模型生成这类文本时,是很难判断是人类生成,还是模型生成;
(2)会阻止模型输出最合适的token,降低生成质量;如输入“Barack”,大多数情况后续接的都是“Obama”这个词,由于随机切分词表,很可能把“Obama”这个token放在red list中,这样致使大模型生成不出最理想的序列。
因此,为了改进sample watermark的缺点,文本提出了sophisticated watermark,接下来我们就看看复杂水印的过程。
2.2 sophisticated watermark

其思路如下:
(1)同样输入prompt序列信息 ,另外增加两个超参数 , ,前者来代表绿色集合占比大小,后者为计算token概率的调节参数;
(2)利用大模型,输入先前序列信息 ,得到t时刻的逻辑向量 ;
(3)同样,利用 token产生一个hash值,然后利用该值产生一个随机种子;
(4)利用产生的随机种子,将词表随机切分成绿色和红色集合,这里两个集合不再等大小,绿色集合大小为 ,红色集合大小为 ;
(5)修改t时刻token的生成概率,具体用参数 结合两个集合来调节概率,形成新的概率 ,利用它进行生成t时刻token,具体计算如下:
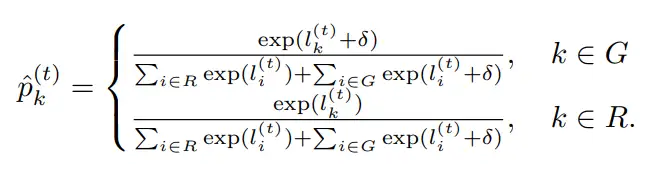
其含义是增加绿色集合token的概率,同时允许token从红色集合采样,只有当红色的token逻辑输出值 特别大的时候才能被采样,这样像上述的例子中,即是“Obama”在red list中,也是能被采样到,不影响输出质量。此外,因为人为的增加了绿色集合token被采样的概率,为了维持分布平衡,需要把绿色集合的变小,所以需要参数 来调节。论文实验中 , 。
对应,sophisticated watermark版本的检测指标z-score需要修改如下:
以上就是给大模型加水印的技术原理,涉及到两个版本,一个简单版本,其等分绿色和红色集合,模型只从绿色集合采样;另一个较为复杂版本,其增加绿色集合token采样概率,减小其大小, 并允许模型从红色集合采样。虽然论文给我们提供一种加水印来检测文本是否由大模型生产的方法,但也不是无懈可击的方案,因为人还是可能修改产生的文本,让文本中的token尽可能在红色集合中,进而避免被检测出。所以,这个方向还有很多值得进一步研究和完善的地方,也是一个很好的写论文点。
参考文献:
[1] A Watermark for Large Language Models
[2]On the reliability of watermarks for large language models
[3]Provable robust watermarking for ai-generated text
[5]Undetectable watermarks for language models
[6]Three Bricks to Consolidate Watermarks for Large Language Models
