
在当今技术驱动的世界中,文本转语音 (TTS) 技术正在成为寻求增强可访问性、自动化流程和更有效地吸引用户的企业的重要资源。随着音频内容在电子学习、客户服务和媒体等平台上越来越受欢迎,对先进、自然的 TTS 解决方案的需求也在上升。
此精选列表展示了可用的顶级文本转语音 API,为业务主管提供了将高质量语音合成集成到其产品和服务中的尖端工具。这些 API 提供无缝、可扩展的解决方案,以改善客户体验、提高生产力并在内容创建领域保持领先地位。
1. 深图
Deepgram Aura 简介:适用于语音 AI 代理的闪电般快速的文本转语音 API
Deepgram 的 Aura Text-to-Speech API 提供快如闪电的类人语音合成,针对对话式 AI、客户支持和语音机器人等实时应用程序进行了优化。延迟小于 250 毫秒,可确保无缝、自然的交互,非常适合优先考虑响应能力和高质量语音输出的企业。
Aura 是一种听起来自然、吞吐量高的文本转语音模型,可提供企业级可扩展性,从而能够以最小的延迟高效处理大量文本转语音转换。它广泛的男性和女性语音选择针对对话用例进行了微调,使其非常适合医疗保健、客户服务和媒体等行业。
Deepgram 的 API 受到顶级企业的信赖,在平衡语音质量、速度和成本方面表现出色,将其定位为寻求集成高级 TTS 功能的企业的领先解决方案。
Deepgram 的主要特点:
Deepgram 的 Aura Text-to-Speech API 提供实时、类似人类的语音合成,延迟小于 250 毫秒。
它针对对话式 AI 和客户支持进行了优化,可确保无缝和自然的交互。
Aura 支持企业级可扩展性,可高效处理大量文本到语音转换。
为各种行业(包括医疗保健和媒体)提供各种经过微调的男性和女性声音。
Aura 深受顶级企业的信赖,可在语音质量、速度和成本之间实现完美平衡。
2. Google Cloud 文本转语音

Google Cloud Text-to-Speech 是一项功能强大且用途广泛的 TTS 服务,它利用 Google 先进的机器学习和神经网络技术从文本中生成高质量、听起来自然的语音。该服务提供多种语言和变体的各种语音,包括可产生高度自然和类似人类语音的 WaveNet 语音。凭借其强大的 API,Google Cloud Text-to-Speech 可以轻松集成到各种应用程序中,使开发人员能够在不同的平台和设备上创建支持语音的体验。
该服务支持多种音频格式,并允许对语音输出进行广泛的自定义,包括音调、语速和音量。Google Cloud Text-to-Speech 还提供文本和 SSML 支持等功能,使其适用于各种用例,从为 IoT 设备创建语音界面到为播客和视频旁白生成音频内容。凭借其可扩展的基础架构以及与其他 Google Cloud 服务的集成,它为希望将高质量语音合成整合到其产品和服务中的企业提供了全面的解决方案。
Google Cloud Text-to-Speech 的主要特点:
WaveNet 语音,实现高度自然和富有表现力的语音输出
Support for multiple languages and voice variants
Customizable speech parameters (pitch, rate, volume)
与其他 Google Cloud 服务集成以增强功能
可扩展的基础设施,可处理不同的工作负载
3. 十一实验室
ElevenLabs 提供最先进的文本转语音 API,该 API 利用先进的神经网络模型来生成高度自然和富有表现力的语音。该平台旨在满足从内容创建到辅助功能工具的广泛应用,使开发人员能够以多种语言和口音生成逼真的语音。ElevenLabs 的 API 以其高质量的输出和自定义选项而闻名,允许用户微调语音特征以满足他们的特定需求。
ElevenLabs 专注于逼真的语音合成,在内容创作者、游戏开发商和希望增强音频体验的企业中广受欢迎。该平台提供预制语音和克隆语音的能力,使用户可以灵活地创建独特的音频内容。ElevenLabs 致力于持续改进和扩展语言支持,这使其成为文本转语音市场的有力竞争者。
ElevenLabs 的主要特点:
用于高度自然语音合成的高级神经网络模型
支持多种语言和口音
用于创建自定义语音的语音克隆功能
可自定义的语音参数,用于微调输出
适用于实时应用程序的低延迟和高吞吐量 API
4. 亚马逊波利

Amazon Polly 是一项基于云的 TTS 服务,它使用先进的深度学习技术来合成听起来自然的人类语音。作为 Amazon Web Services (AWS) 生态系统的一部分,Polly 提供了多种语言和口音的广泛语音,使开发人员能够创建能够以逼真的发音和语调说话的应用程序。该服务旨在轻松集成到现有应用程序、网站或产品中,使企业能够增强用户体验和可访问性。
Polly 的神经文本转语音语音提供更自然和富有表现力的语音输出,使其适用于各种使用案例,包括电子学习平台、辅助功能工具和支持语音的设备。该服务还支持语音合成标记语言 (SSML),允许对语音输出进行精细控制,包括强调、音调和语速。Amazon Polly 采用即用即付定价模式,为各种规模的企业提供了一种经济高效的解决方案,可将高质量的语音合成整合到其产品和服务中。
Amazon Polly 的主要功能:
多种语言和口音的栩栩如生的声音
神经文本转语音技术,增强自然度
支持语音合成标记语言 (SSML)
与 AWS 生态系统和其他应用程序轻松集成
即用即付定价模式,实现经济高效的扩展
5. Microsoft Azure
使用 Azure AI 语音创建个性化语音
Microsoft Azure 的文本转语音服务是 Azure 认知服务套件的一部分,提供全面且可扩展的解决方案,用于将文本转换为逼真的语音。利用 Microsoft 在神经文本转语音技术方面的广泛研究,该服务提供了多种语言和变体的各种自然语音。Azure 的 TTS 旨在与其他 Azure 服务无缝集成,使其成为已经使用 Azure 生态系统的企业的一个有吸引力的选择。
该服务提供灵活的部署选项,允许用户使用容器在云中、本地或边缘运行 TTS。这种多功能性与 Azure 强大的安全功能和合规性认证相结合,使其特别适用于企业级应用程序。Azure 的文本转语音还支持创建自定义语音,使组织能够开发独特的品牌语音,从而在各种接触点获得一致的音频体验。
Microsoft Azure 文本转语音的主要功能:
用于高度自然语音输出的神经语音
灵活的部署选项(云、本地、边缘)
自定义语音创建功能
与其他 Azure 认知服务集成
企业级安全性和合规性功能
6. Play.ht
Play.ht 快速导览 - 最好的 AI 语音生成器!
Play.ht 提供了一个多功能的 TTS API,可以访问 800 种语言和口音的 142 多种 AI 语音。该平台专为可扩展性和实时应用程序而设计,延迟低于 300 毫秒。Play.ht 的 API 同时支持 REST 和 gRPC 协议,适用于广泛的项目和集成场景。
Play.ht 的突出特点之一是它能够生成具有上下文感知和情感范围的高质量、自然的声音。该平台还提供语音克隆功能,允许用户根据其特定需求创建自定义语音。Play.ht 专注于高保真输出和流式处理功能,非常适合从内容创建到实时对话式 AI 的各种应用程序。
Play.ht 的主要特点:
超过 800 种逼真的 AI 语音,涵盖 142 种语言和口音
低延迟(低于 300 毫秒),适用于实时应用程序
语音克隆和自定义选项
支持 REST 和 gRPC API 协议
适合流式传输的高保真输出
7. Murf.ai

Murf.ai 提供了一个文本转语音 API,专注于为各种应用程序提供高质量、类似人类的声音。该平台提供 120 种语言的 20 多种语音,确保灵活地满足不同的语言要求。Murf.ai 的 API 旨在与现有技术堆栈无缝集成,使其成为希望将文本转语音功能整合到其产品或服务中的企业的合适选择。
虽然 Murf.ai 可能无法提供市场上最低的延迟,但它通过强调语音质量和自定义选项来弥补这一点。该 API 允许用户微调生成语音的各个方面,包括音高、速度和强调。Murf.ai 还提供团队协作和角色管理功能,使其对于从事内容创建项目的组织特别有用。
Murf.ai 的主要特点:
超过 120 种高质量语音,涵盖 20 种语言
语音输出的广泛自定义选项
团队协作和角色管理功能
与多个语音提供商(例如 Google、Amazon、IBM)集成
支持各种音频输出格式(MP3、WAV、FLAC)
8. 开放人工智能
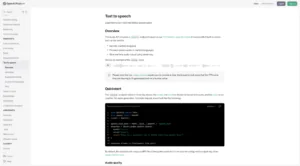
OpenAI 的文本转语音 API 利用先进的深度学习模型从文本输入生成自然且富有表现力的语音。虽然与其他一些产品相比相对较新,但 OpenAI 的 API 由于其高质量的输出和公司在尖端 AI 研究方面的声誉而迅速受到关注。API 提供了一系列预设语音,并支持针对不同使用案例优化的两种模型变体。
OpenAI 的文本转语音 API 的优势之一是它能够捕捉语调和表情中的细微差别,从而产生听起来非常自然的语音。该 API 旨在轻松集成到各种应用程序中,并支持实时用例的流式处理功能。虽然它可能无法像某些竞争对手那样提供那么多的语音或语言,但 OpenAI 对质量和持续改进的关注使其成为寻求最先进语音合成的开发人员的引人注目的选择。
OpenAI 的文本转语音 API 的主要功能:
高质量、自然的语音合成
针对不同用例优化的模型变体
支持流式音频输出
与现有应用程序轻松集成
基于 OpenAI AI 研究的持续改进
9. IBM Watson 文本转语音

IBM Watson Text to Speech 是一种基于云的 API 服务,可将书面文本转换为各种语言和语音的自然音频。Watson TTS 利用先进的人工智能和深度学习技术,使企业和开发人员能够通过高质量的语音交互来增强其应用程序、产品和服务。该服务旨在通过允许品牌以用户的母语与用户交流来改善客户体验,提高具有不同能力的个人的可访问性,并自动化客户服务交互以减少等待时间。
Watson TTS 的优势之一在于其灵活性和定制选项。用户可以使用 SSML 微调生成的语音的各个方面,包括发音、音量、音调和速度。该服务还提供神经语音以实现更自然和富有表现力的输出,以及通过其高级层创建自定义品牌语音的能力。凭借其集成功能,尤其是与 Watson Assistant 的集成功能,IBM Watson Text to Speech 为希望将高级语音技术整合到其产品中的企业提供了全面的解决方案。
IBM Watson Text to Speech 的主要功能:
神经语音,可实现高度自然和富有表现力的语音输出
支持多种语言和方言
使用 SSML 的可自定义语音参数
与 Watson Assistant 集成以增强对话式 AI
创建自定义品牌语音的选项(高级功能)
最后
正如我们所探索的,文本转语音技术领域充满了创新解决方案,可满足各种需求和用例。从 Amazon Polly 与 AWS 的无缝集成到 ElevenLabs 的高级语音克隆功能,这些 API 正在突破语音合成的界限。神经网络和深度学习的持续进步不断提高合成语音的自然性和表现力,使其与人类语音越来越难以区分。
展望未来,文本转语音 API 的未来似乎非常有希望。随着企业和开发人员继续利用这些强大的工具,我们可以期待看到更复杂的应用程序出现,从个性化的虚拟助手到身临其境的游戏体验。在这个快速发展的领域中,成功的关键在于选择符合您特定要求的正确 API,无论是多语言支持、低延迟还是自定义选项。通过利用这些尖端的文本转语音解决方案,组织可以增强可访问性,提高用户参与度,并解锁内容创建和交付的新可能性。

